Note: The concept posited in this article are developed through author’s own observation

Mukbang Show
From gestures and spoken languages to books, radios and TV, civilisations have witnessed pretty much an immense proliferation and complication of how we communicate. Many are lost, yet one could not deny that our communications have never been so multimodal – a single platform can afford virtually every mode of communication (e.g., unilateral mass communication, personal messaging, vlogging, etc.) Understandably, the more is not the merrier. We need not the most complicated form of communicating to attract audience, let alone the content which aims are not to boost interaction.
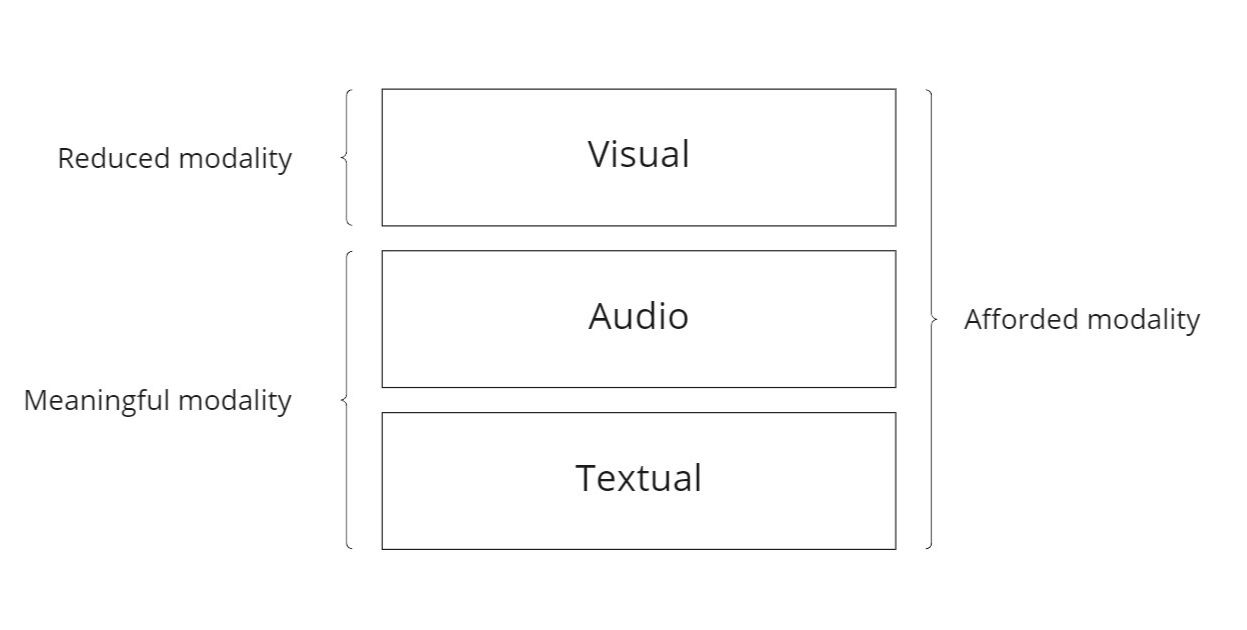
The intriguing phenomenon is, nevertheless, the reduction of modality without actually removing it from our visual sense. Though appears to be rather complicated, it can be comprehended through the comparison of various YouTube genres.
Genres, purposes and modality entanglement
Not all content creators and users fully utilise the afforded functionalities of YouTube and indeed content does differ in the ways that they are presented across genres. Here I propose a few interconnected preliminaries in demarcating genres as a foundation to further explore the phenomenon of reduced modality.
Purpose of the video matters in determining the necessity of certain modalities to be used. Let’s take vlog as an example: you need to tell a story – a trip to Leiden. To illustrate what Leiden is, the vlog should be designed in a way that allows for the conveyance of a consecutive and co-dependent segments of narratives to the audience. To serve this purpose, the presence of multiple forms of visuality and modes of media is necessary. Conceivably, before the possibility of visual recording, humans rely much on the rather unimodal, indirect and vague forms of communication such as viva voce and written words, though illustrations and paintings, as complementary parts of these communications, have been available since 70,000 years ago during the Stone Age. Despite the long-standing existence of visual representation of knowledge and reality, perhaps the most remarkable advantage of multimodality is that the modality supports each other to form a more complete picture of what reality is. Thus, going back to the example of the Leiden vlog, to be able (re)present what Leiden is, audios, visuals and other types of texts can well be used to achieve such purpose.
In turn, the purpose of the communication is very much intertwined with the process of sense-making and meaning-making. Storytelling is all about sense-making, a state where we are “being thrown into an ongoing, unknowable, unpredictable streaming of experience in search of answers to the question, “‘What’s the story?'”, but not so much about other communications which do not in essence serve the purpose of storytelling, or those which are not deemed to do so. Indeed, the Uses and Gratifications Theory has long told us that there is no singular reason why one would consume certain media content. Neither everyone watches the Leiden vlog to get to know more about the city (e.g., the audience may be watching the vlog for a class), nor we can take it as a matter of course to assume that the producer is trying to tell a story (e.g., the producer may be making the vlog for study credits). As a result, both intended purposes of the video and audience’s needs define largely whether sense-making processes are in place or not.
A concept I would like to introduce here is, as a component within the phenomenon of reduced modality, modality entanglement. Since storytelling is not a prerequisite for communications, certain modalities are in fact not needed to satisfy the motivation behind the production and consumption of these content. As depicted in the picture below, there are videos with only music without any motion pictures involved. Certainly, having a black screen is not an arbitrary choice – the “video” is meant to be a background music for sleeping.

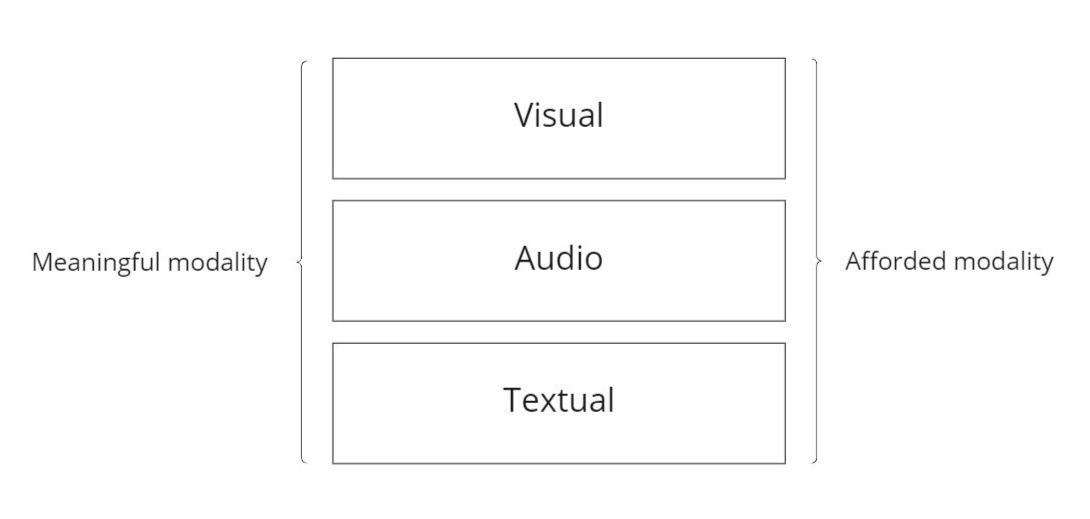
On the contrary, meaningful modality entanglement refers to the need for co-existence of modalities to fulfill communication purposes.
The unsolved problem of reduced modality
In reality, it is not often possible to include all kinds of modalities due to several structural, technical and practical reasons, for instance the lack of materials (e.g., you do not have a video of Leiden) and limitation of affordances (e.g., the platform you are using does not allow videos).
Yet, there is still an unsolved mystery – the deliberate inclusion of modalities meanwhile the modality entanglement is not necessary. The inclusion of these redundant modalities does not refer to the inefficient communication practices like adding too much colour to a powerpoint, but points to the use of an additional modality on top of another to serve another purpose. These added elements, though, do not add any value to the sense-making processes to one another. An example is the renowned Mukbang 먹방 (eating show) broadcaster Stephanie Soo, in which she produced videos about true crime / scary stories in the course of food tasting. As obvious as it seems, the eating part is completely detached and irrelevant to the stories that she is telling and it does not aid the sense-making processes, neither does the story help the audience watch them eating.
What makes Stephanie Soo’s content so different than other Mukbang broadcasters like 설기양SULGI and GONGSAM TABLE 이공삼 is that her videos are not primarily about eliciting audio-induced Autonomous Sensory Meridian Response (ASMR), but more of a hybridity with storytelling. I argue that such content cannot be explained merely by neurobiological sciences (e.g., neuroticism) or social and behavioural psychological theories like parasocial relationships, which have been examined in scholarly research on Mukbang and meal-concurrent media use.
Therefore, there is a theoretical need to further explore such novel technique in which a meaningful layer of modality is consciously deprived, or reduced, and inserted with a totally incoherent stratum of one.
Re-examining purposes: Symbiotic or Detached Plurality?
This leads back to the preliminaries I mentioned at the beginning – what are the purposes of the videos? The plurality of purpose no more exist only within the audience, but also the content creators themselves. Of course, media producers must have multiple purposes when they manufacture anything, be it telling a story or making people laugh, but these content all require the same set of modality entanglement in order to achieve these purposes (e.g., need for audiovisual elements to tell a story and make people laugh). In contrast, in the case of Stephanie Soo, despite that Mukbang has its own set of entanglement to facilitate sense-making, the verbal modality of true crime storytelling is added to Mukbang, meanwhile the visual modality of true crime is deprived.
Hence, the plurality here demonstrates purposes that demand dissimilar combinations of modality entanglement. The question is then if these separable collections of entanglement are in a relationship of symbiosis or detachment. To put it briefly, do Stephanie Soo’s selection of modalities serve purposes only Mukbang/true crime can offer, or a varying levels of purposes that Mukbang and true crime shows can independently provide. Perhaps before reaching the answer, we ought to ask ourselves the question: how can we classify her videos in a valid manner – are they mukbang or true crime?
All in all, the rationale behind the constructions of the new concepts is to dissect the particular phenomenon of reduced modality in such neoteric multimodal and collaborative media content, which functionalities are well afforded by the platforms. Albeit the phenomenon has never been empirically investigated, I believe that the concept of modality entanglement has the potential to be expanded to offer new insights about our digital sphere.


Recent Comments