As someone who is studying a language, I’ll be the first to preach to you the importance of vocabulary practice. I can’t stand not being able to talk to someone just because I don’t know the right word for ‘shovel’, for example. This has led me to take my vocab practice much more seriously, to the point where I’m often reviewing words during classes to keep up my daily grind. To be more specific, I use a tool called ‘Wanikani’, which helps users to memorize a boatload of Japanese words, and more importantly, kanji. These kanji are the logographic characters people often associate with East-Asian languages. By typing the characters’ reading and meaning, the user ‘levels up’ and is allowed to advance to the next stage Wanikani has to offer, meaning more stuff to memorize.
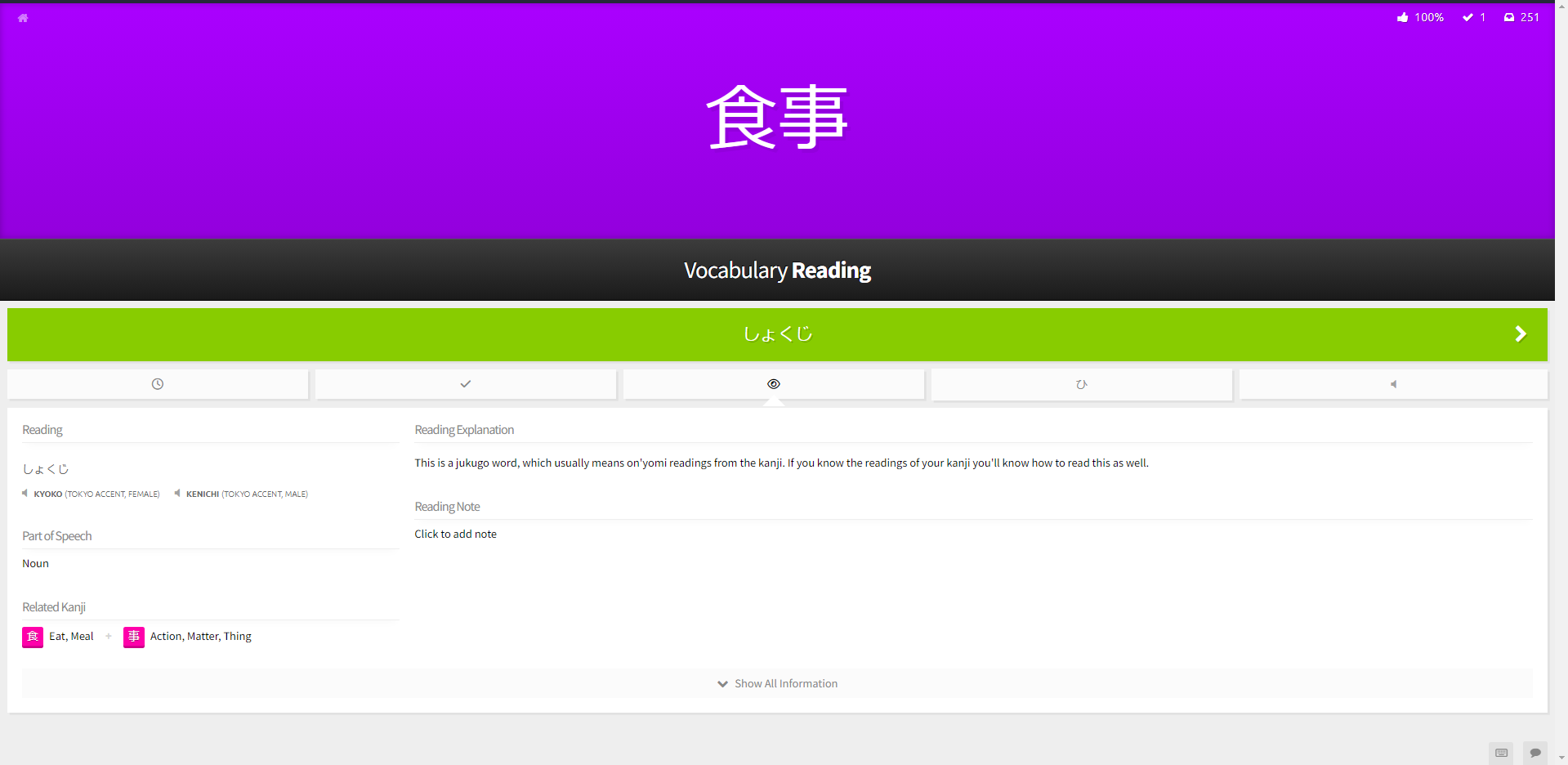
Anyway, recently someone asked me how in god’s name I was typing out these Japanese words on my western keyboard. This isn’t the first time someone asked me this, so I just gave them the standard, surface-level explanation. By writing the Japanese words with the Roman alphabet, Windows automatically converts them to Japanese. This system is called an Input Method Editor (IME) and it exists for many other non-Roman alphabet languages too. Later that day, however, I was thinking back on that conversation. How much do I actually know about this process? Well, I did some research and I would like to tell you once and for all how this system works.
Let’s focus on the Japanese language for this blog post. To give some linguistical context, Japanese has three alphabets: hiragana (ひらがな), katakana (カタカナ), and kanji (漢字). The first two can be confined to their own group, namely kana (仮名). These alphabets are syllabaries, meaning that they consist of syllables or moras instead of individual letters, and don’t mean much on their own compared to the logographic kanji characters. hiragana and katakana combine to a total of 92 characters, 142 if you include diacritics. Thankfully, while the characters look different, they indicate the same sounds (あ and ア both mean ‘a’, for example).
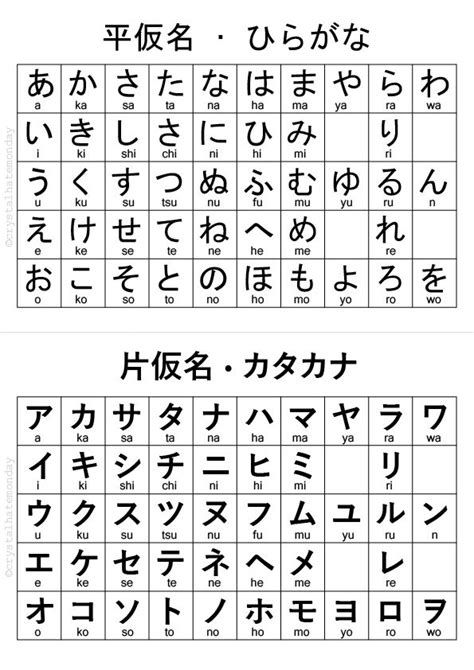
While one could theoretically write out a full-length Japanese novel using just kana (as kanji words can be written out using kana), kanji characters are used for the sake of readability and the fact that there is an abundancy of homonyms in the Japanese language. Take the sentence “My mother likes flowers”, for example. If just kana is to be used, it would end up as ははははながすき, making it a bit difficult to distinguish the beginning and ending of certain words. Converting the words into kanji gives us the much more readable 母は花が好き.

That brings me to the next major function of the Japanese IME, converting kana into kanji. When a user types out a word in kana, a dropdown menu suddenly appears. This menu, called the “conversion candidate window”, shows you a list of kanji characters that the typed kana can be converted to. The order of these kanji characters is based on the general frequency of said character in Japanese and the user’s recently typed words. So, if the user would like to type the kanji characters for ‘today’, the following flowchart will occur:
- The user types kyou
- kyou is automatically converted to きょう by the IME
- The user presses the spacebar until the right characters are being highlighted in the conversion candidate window and the kana is converted to 今日
- The user presses the enter key to end the process
In the case of a homonym, the user simply presses the spacebar multiple times until the correct kanji character is selected. An example of this would be the character for ‘teach’, which is also spelled as きょう in kana but normally needs an additional push of the spacebar to be converted to 教, as the system dictionary deems it to be less common than 今日.
While this system definitely took some getting used to, it is extremely well-designed and it is the most efficient way to type Japanese characters. Even in Japan, where there are keyboards designed with the language in mind, ロマ字入力 (romanized input) is still more popular among Japanese people than 仮名入力 (kana input). This might be due to the fact that more keys, like the number row on top, are used for kana characters, making remembering every location a bigger pain. Having quick access to the Roman alphabet is also a near-necessity for internet users, as URLs can’t be entered with kana.
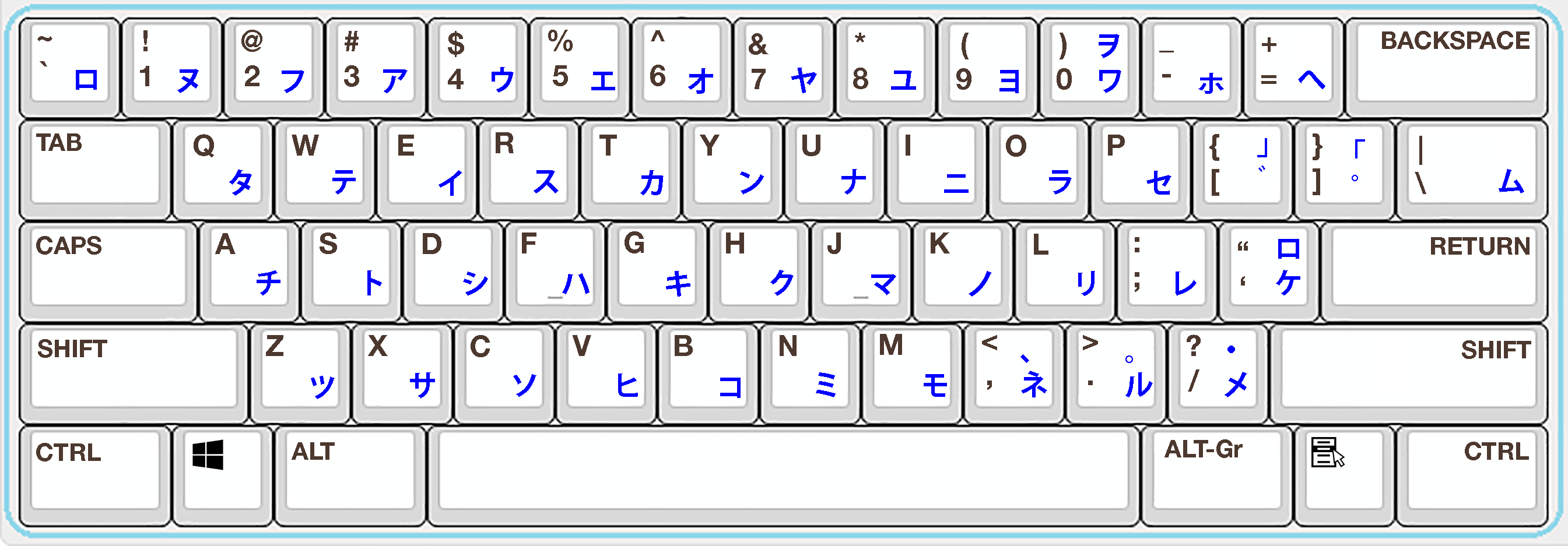
I hope I have shed some adequate light on the workings of IMEs (concerning the Japanese language in particular). If you have any sort of further interest in the way these non-Roman alphabets got to the point they are now in the digital age, I highly recommend this video by Junferno. He goes further in-depth about the history of keyboard layouts in different languages and how they have evolved from the days of the typewriter to now, in the digital age.


Interesting post! As a linguist, this type of technological system to facilitate language learning is very exciting. For my Korean-learning, I would just place stickers on my keyboard that corresponded to their location on the romanised keyboard, super technologically advanced and practical for when you’re typing a lot (not- the stickers fall off and fade). Very cool, thanks for the post!